Running Local LLMs with DFlash for Agents
起因是看到一条关于 Qwen3.5-27B 在 RTX 3090 跑出 207 tok/s 的推文;DFlash 在本地推理上的加速效果很惊艳,而家里的 RTX 4090 平时也经常闲着;LuceBox Hub 的结果基于 RTX 3090,我想看看 RTX 4090 上能跑出什么结果。
原始 DFlash benchmark 复现
我先在 Claude Code 的辅助下尝试复现原始 benchmark。环境初始化、依赖安装、CUDA 扩展构建、数据整理,基本都是通过聊天完成。第一轮复现得到下面这些数据。
DFlash 的原始 benchmark 是 Qwen3.5-27B Q4_K_M target + DFlash draft,n_gen=256,每个数据集 10 个 prompts。
| 数据集 | GPU | AR tok/s | DFlash tok/s | AL | Speedup |
|---|---|---|---|---|---|
| HumanEval | 3090 README | 37.78 | 129.52 | 8.31 | 3.43× |
| HumanEval | 4090 实测 | 42.55 | 147.90 | 8.01 | 3.48× |
| GSM8K | 3090 README | 37.65 | 96.15 | 6.14 | 2.55× |
| GSM8K | 4090 实测 | 42.51 | 127.94 | 6.89 | 3.01× |
| Math500 | 3090 README | 37.71 | 110.51 | 7.04 | 2.93× |
| Math500 | 4090 实测 | 42.52 | 132.32 | 7.12 | 3.11× |
这组数据看起来很好。从 3090 README 到 4090 实测,AR baseline 从 37.7 tok/s 左右上到 42.5 tok/s 左右,DFlash 从 96-129 tok/s 上到 128-148 tok/s——这是硬件差异,不是优化。整体 speedup 仍在 3× 左右。
这个结果看起来激动人心,我就迫不及待想接入到 Pi 中使用。能有这个速度,那作为日常助手的 agent 就不用独立买一个 Kimi Coding Plan,直接使用 Local LLM 就可以了。
为 llama.cpp server 添加 DFlash + DDTree 的支持
LuceBox Hub 仓库里的 server.py 是最简单的 benchmark server。它没法直接接入 Pi 做真实 agent workload 测试。翻查后发现 Luce Team 有一个 fork 版本的 llama.cpp 在推进相关改动,但还不完整。
我当时也查了 llama.cpp 上游的实现状态:server: speculative checkpointing 已经在 #19493 合并;speculative-simple: add checkpoint support 已经在 #22227 合并;但 DFlash 相关的 #22105 还是 draft,并且依赖 EAGLE3 的 #18039。另一个相关 PR 是 GDN partial seq_rm 的 #22400。
GPT-5.5 刚上线不久还没尝鲜,我就让 GPT-5.5 协助推进 llama.cpp 这边的实现。Python 参考实现已经存在,社区也有相关工作,一天左右后 Codex 报告“可以了”。
第一轮真实测试体感很差,和原始 benchmark 的差距很大。最初我以为只是参数问题,于是在 Pi 里面启动了 autoresearch,让 GPT-5.5 自动测试各种组合。
Autoresearch 跑了什么
Autoresearch 断断续续跑了 224 个 run:
| 状态 | 数量 | 含义 |
|---|---|---|
| keep | 20 | 正向有效结论 / 新 best / 保留点 |
| discard | 180 | 负向有效结论 / 证伪方向 |
| crash | 24 | 没有有效 benchmark 结果 |
换句话说,有效 benchmark 结论是 200 个,其中正向有效结论是 20 个。
压缩后的结论如下:
- 1024-token target feature window 太慢。
target_feat_ctx=128是早期甜点。- Decode-only TPS 比 end-to-end TPS 更适合作为调优指标。
- Budget 增大到 32/40 能改善 accepted path。
- Proposal temperature 最佳区间在
0.7左右。 top_k=4足够,K>4收益不明显。- Pure best-first /
chain_seed=0更适合当时的 exact path。 - Fast rollback 在 64k context / full-draft / 24GB VRAM 下不适合作默认路径。
- CUDA graph、batch、KV、q8/q4、offload 等微调都不能稳定改善。
但这 224 轮次 autoresearch 之后的结果是 TPS 10.666,step 214ms,draft 141ms,top-k 15ms - 这个结果不对劲。Python standalone DFlash 能轻松破百 token/s,但跑了一天多 autoresearch 的结果还不如 vanilla llama.cpp。
停下来复核实现后,我发现又被 GPT-5.5 坑了。它把 P0 任务判断成“跑得动”,而不是“完整实现 DFlash + DDTree 的高性能路径”。也就是说,llama_decode 路径还和 DFlash/DDTree 的理想执行路径有很大差距,但 autoresearch 一直在做参数搜索,而不是从更高层的实现路径上调整。
这个教训很明显: GPT-5.5 能发现问题,但不能放心让它排优先级。它容易把文档对齐、小瑕疵、边缘 clean-up 当成 P0/P1。一旦注意力走偏,短时间内很难拉回来。
DFlash draft runtime and DDTree verify
虽然还是 GPT-5.5 敲定了接下来的目标,我还是切换到 Claude Code 推进执行事项:添加 DFlash draft runtime 和 DDTree verifier。
在开始之前,我记录下以下基准数据;这个版本能通过 OpenAI-compatible API 生成 token,也能跑 thinking 和 tool use:
step_ms=214.29
draft_ms=140.90
topk_ms=14.71
exact_ms=57.53
acceptance=2.357Speculative decoding(先让 draft model 猜一段,再让 target model 验证)要有专用 draft path,不能继续走通用 llama_decode。在加入专用 DraftBackend 和 draft runtime 后,数据明显改善:
step_ms=86.31
draft_ms=27.71
topk_ms=0.00
exact_ms=58.58
acceptance=1.941| 指标 | 前 | 后 |
|---|---|---|
| step_ms | 214.29 | 86.31 |
| draft_ms | 140.90 | 27.71 |
| topk_ms | 14.71 | 0.00 |
| exact_ms | 57.53 | 58.58 |
| acceptance | 2.357 | 1.941 |
draft_ms 从 140.90ms 降到 27.71ms,topk_ms 也被消掉。
接下来就是 DDTree,把 DDTree verify path 改成更接近论文的路径:
DFlash draft top-K
-> DDTree proposal
-> target tree attention verify
-> posterior tree walk
-> KV compact + recurrent/conv rollback
-> commit + bonus tokenDDTree verifier 跑通并保持 bit-equal,这是工程上很重要的节点。但初版 DDTree verifier 的 default exact path 在短测中的结果退化了,target_tree_ms 增加了。
真正的大提升来自 grammar-free DDTree verify。agent traffic 里 tool-call grammar 的 sampler callback 很慢。instrumentation 显示:
n=4247 cb samples
sync avg = 0.004 ms
work avg = 47.978 ms
p90 work = 105 ms也就是说,慢的不是 GPU sync,而是 grammar-active tool-call schema 下的 host-side sampler/grammar work。DFlash/DDTree reference verify 本来就是 target greedy argmax,不应该在 verify walk 里跑 grammar。grammar 只需要在主 sampler commit path 推进。
关掉 verify walk 的 grammar 后:
agent TPS API: 8.90 -> 14.15 (+59%)
accept_path: 30-110 ms -> 0.01 ms这就是 speculative mode 内部最好的结果。
真正的 baseline:vanilla llama.cpp
到这里还不能说 DFlash 对 agent 有收益,因为我们一直在跟旧 spec path 比。真正的 baseline 应该是不开 spec 的 vanilla llama.cpp。
继续在 RTX 4090 上进行测试,同一个 Qwen3.5-27B Q4_K_M,同类 agent traffic,plain llama-server 的结果是:
TASK TPS 32.57 tok/s API
wall 24.60 tok/s
single-token eval ~= 24 ms/token横向对比:
| 阶段 | Agent TPS API |
|---|---|
| Earliest DFlash recorded | 6.96 |
| DFlash draft runtime chain mode | 11.07 |
| DDTree grammar verify | 8.90 |
| DDTree budget=22 | 9.28 |
| DDTree grammar-free verify | 14.15 |
| Vanilla AR | 32.57 |
这时对比口径变了:DFlash draft runtime 和 DDTree verify 的优化都是真的,但它们只是在 speculative mode 内部变快。面对 vanilla AR,14.15 tok/s 仍然低于 32.57 tok/s。
原因是 acceptance length 太低。Acceptance length (AL) 指一次 spec step 平均能提交几个 token。原始 HumanEval / GSM8K / Math500 benchmark 的 AL 都大于 6,而当前 agent workload 的 AL 大概只有 2。
break-even 很简单:
spec step_ms ≈ 110 ms
vanilla per-token ≈ 24 ms
spec wins iff 110 / AL < 24
AL > 4.6agent traffic 实测 AL 大概只有 2,差太远。
为什么 agent traffic 的 AL 低
后面我借助 AI 学习了一轮论文,也回头看了 DFlash 的训练分布。根因是 draft model 针对自然聊天和常规 benchmark 训练,没有针对 agent traffic 训练。
agent traffic 包含以下模式:
- tool-call JSON schema
- system prompt 里的 tool definitions
<think>/<tool_call>markers- 多轮 tool response
- 长上下文
- 高频短输出
DFlash draft 没在这种分布上训练。因此 draft 预测出来的很多 token 在 verify 阶段都会被丢掉。
我还做了三组排除实验:
- 剥掉 chat/tool template 后,AL 从 2 提到 3.2 左右,但仍低于 break-even 4.6。
- 用 oracle gate 提前知道每一步 AL 后,最优策略仍然是不走 spec,因为没有一步 AL 达到 break-even。
- reference safetensors path 在 agent prompt 上也只有 AL 2.7-3.2,说明问题不是 GGUF port 单独造成的。
这三组实验说明,agent AL 低不只是 GGUF port 或 llama.cpp fork 的问题。实现有二次损失,但 draft training distribution mismatch 是更大的因素。
此时如果我们去翻查 z-lab 的 Hugging Face collection和公开资料,目前并没有公布他们的 DFlash draft model 训练方法;虽然 SGLang 社区有一个实现,但是要针对 agent traffic 进行训练,这显然不是本地 RTX 4090 能完成的事情了。
vLLM 和 SGLang 已经支持 DFlash 了,结果如何?
为了排除“是不是 llama.cpp fork 不行”,我又看了 vLLM / SGLang 的 DFlash 路线。
结果更差:
- 受限于显存大小,在测试中 vLLM 只能用 Qwen3.5-27B-AWQ 版本。这里要注意一个坑:QuantTrio 发的是 VLM 变体,里面的 fp16 vision encoder 不被 AWQ 量化,所以本体就要 21.85 GB,加 DFlash BF16 draft 3.3 GB,已经超过 24 GB。强行用
--cpu-offload-gb 18 --enforce-eager能跑起来,实测 0.94 tok/s、AL 1.38。 - SGLang 遇到 tied weights 冲突 bug,跑不起来。考虑到同样的显存约束,我没有继续投入。
所以这两条都没进核心对比。vLLM 那 0.94 tok/s 主要是 CPU offload 的拖累,target 大头权重在 CPU 上、每层 forward 都要搬一次,这数字反映不了 DFlash 本身好不好。它只能说明 24GB 单卡装不下 AWQ-VLM target + DFlash draft 这套组合。SGLang 装得下但跑不起来,没东西可比。
把 Gemma 4 加入评测
最后我加了一个 cross-architecture 对比。这也符合我日常的偏见:我一直觉得 Qwen3.5-27B 在 agent 使用中没有 Gemma-4-31B 好使。
同样是 llama.cpp vanilla AR,同类 agent workload。这里 Qwen vanilla 是 13.22 tok/s。和前面 vanilla baseline 跑出来的 32.57 不一样:前面那次是 driver 560 下的长会话样本,这次是 driver 595 升级后跑的短会话(2 reqs / 311 token 输出),prefill 占比高把 API TPS 压下来了。两个数都对,是不同 sample。Gemma 这次跑的也是短会话,跟 Qwen 的 13.22 同口径:
| Model | API tok/s | Wall tok/s | Raw decode | Prefill | VRAM | 配置 |
|---|---|---|---|---|---|---|
| Qwen3.5-27B Q4_K_M | 13.22 | 10.06 | 43.7 tok/s | 521-865 tok/s | 15.5 GB | driver 595 |
| Gemma-4-31B Q4_K_M | 29.30 | 24.97 | 35.0 tok/s | 366-2416 tok/s | 18.0 GB | ngl 61, SWA 1024 |
这个对比很有意思。Qwen 的 raw decode 更快:43.7 tok/s vs 35.0 tok/s。但 Gemma 的 agent API TPS 高很多:29.30 vs 13.22,约 2.22×。
原因是 agent workload 不只是 decode。它有大量 prompt ingest、cache revalidation、tool roundtrip 和短输出。Gemma 4 的 sliding window attention(SWA)和 shared KV layers 让长 context prefill 更便宜,所以 agent 层吞吐反而更高。
这条数据说明,在同一类 agent workload 下,Gemma-4-31B 的 API TPS 明显高于 Qwen3.5-27B。
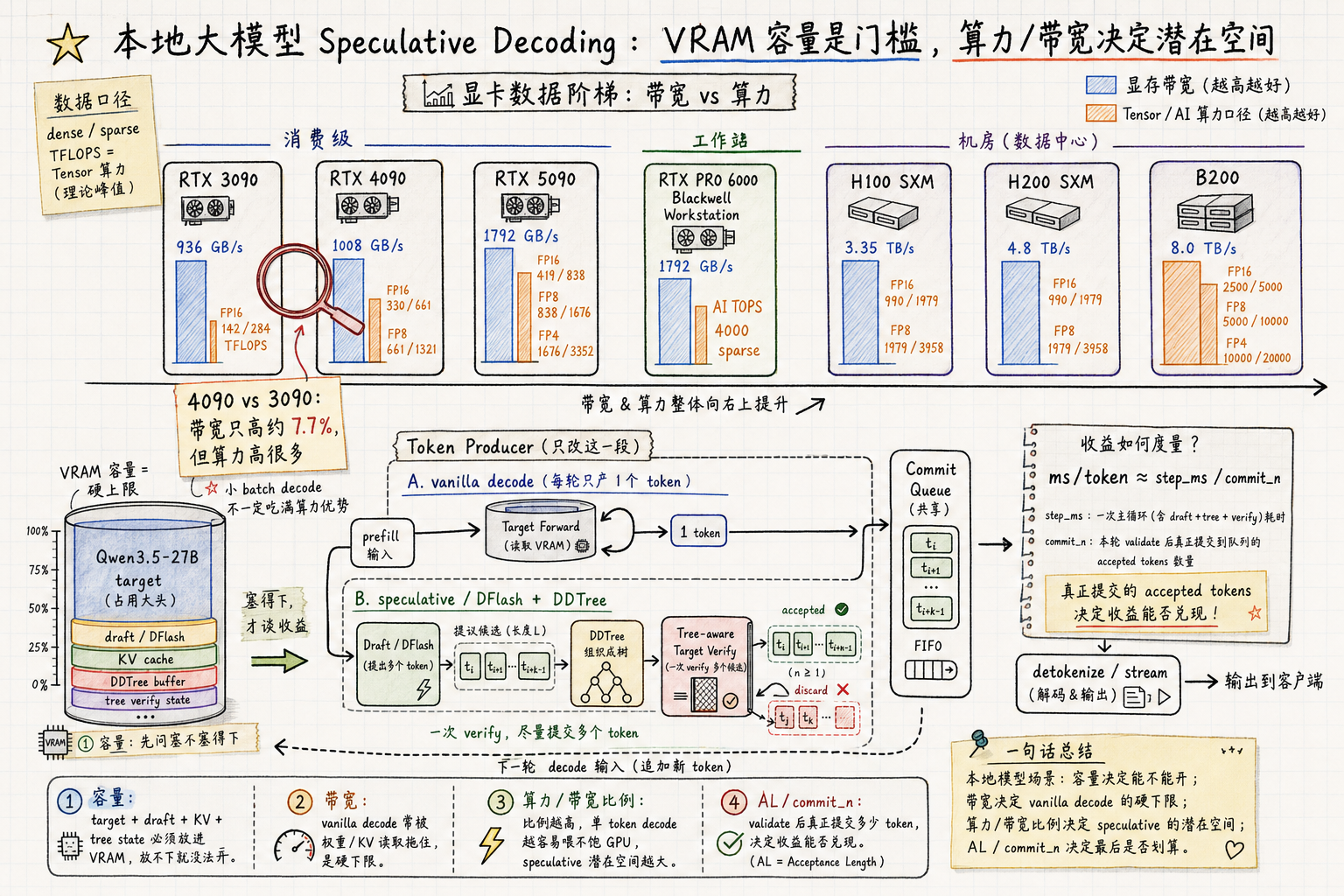
什么是 Speculative Decoding?
既然已经碰到自己的盲点,那自然需要恶补一番。感谢 Codex 客户端,感谢 GPT Image 2。通过对话,我整理这个图来帮助理解(记忆)什么是 speculative decoding。
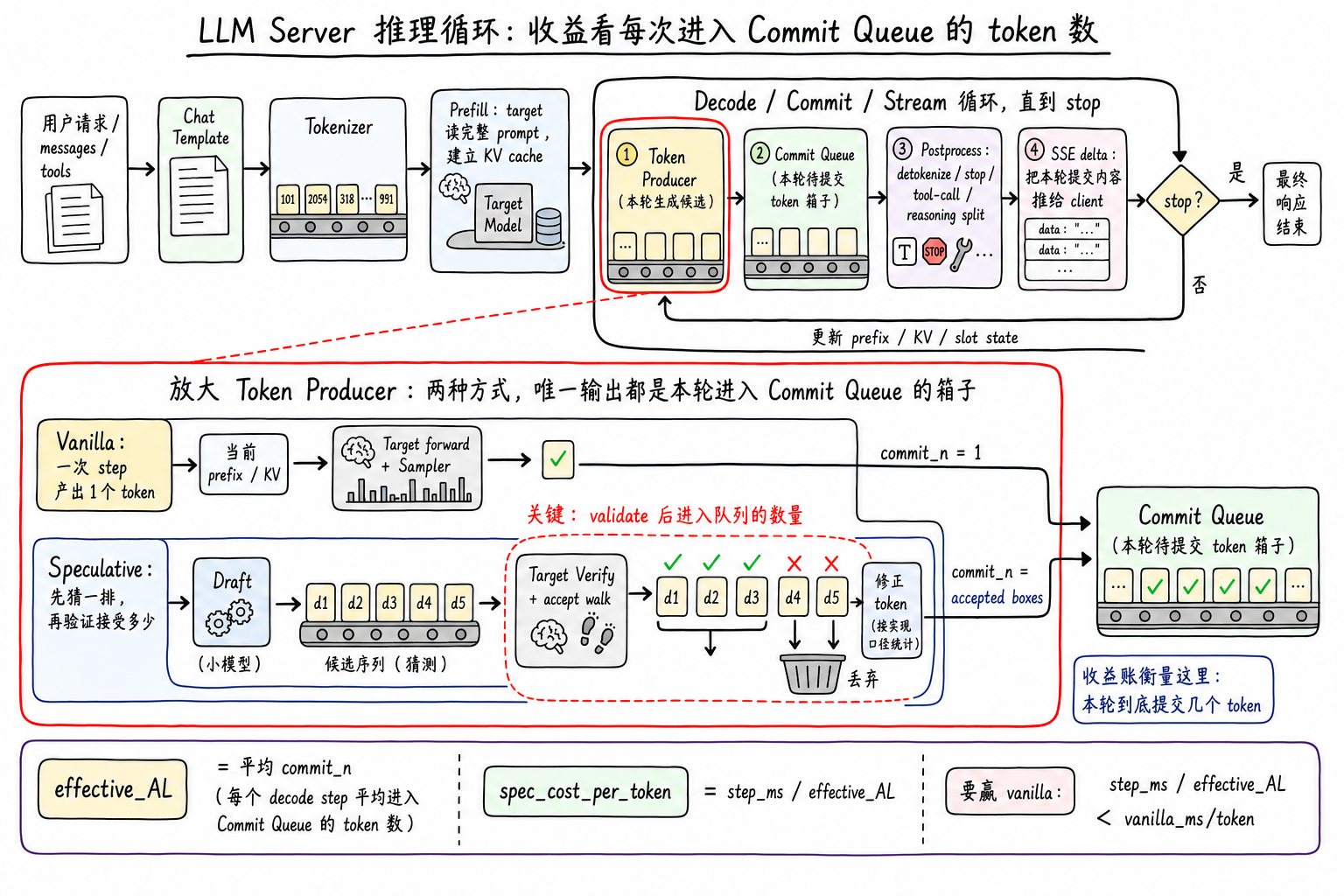
在 decode 环节,把原本一次只吐一个 token 的流程,变成一次吐多个 tokens、并把结果送进 commit queue 的流程优化,而这个算法需要一个额外的 draft model。
这里需要注意的细节点:
- 除了原本的推理模型,你还需要一个 draft 模型。
- draft 模型本身也消耗 VRAM。
- draft 模型需要和推理模型匹配,否则是负增益。
- Speculative decode 会引入额外的 draft/verify 开销,这里就有一个潜在的收益评估,就是图中的 effective AL (acceptance length)。
Speculative decoding 还有一些细节概念,包括 accepted tokens, bonus token, correction token, 这里可以理解为在 target verify 阶段进行的行为,也可以用来衡量 draft model 的“效能”。我们把 draft model 产生的 token 叫做 draft tokens,那么:
- 如果 draft tokens 都被接纳了,那么 target verify 阶段就会多给一个 token,这个 token 就是 bonus token,最终进入 commit queue 的 accepted tokens = draft tokens + bonus token。
- 如果 draft tokens 只有部分被接纳(或者完全不被接纳),那么 target verify 也会给一个 token,这个 token 叫做 correction token(也等于保底至少产出一个 token)。那么最终进入 commit queue 的 accepted tokens = accepted draft tokens + correction token。
简单来说,统计 bonus token 和 correction token 的比例可以用来评估 draft model 的效果。
什么是 DFlash 和 DDTree?
Speculative decoding 是一个框架,而 DFlash 和 DDTree 就是这一框架下的两个组件。
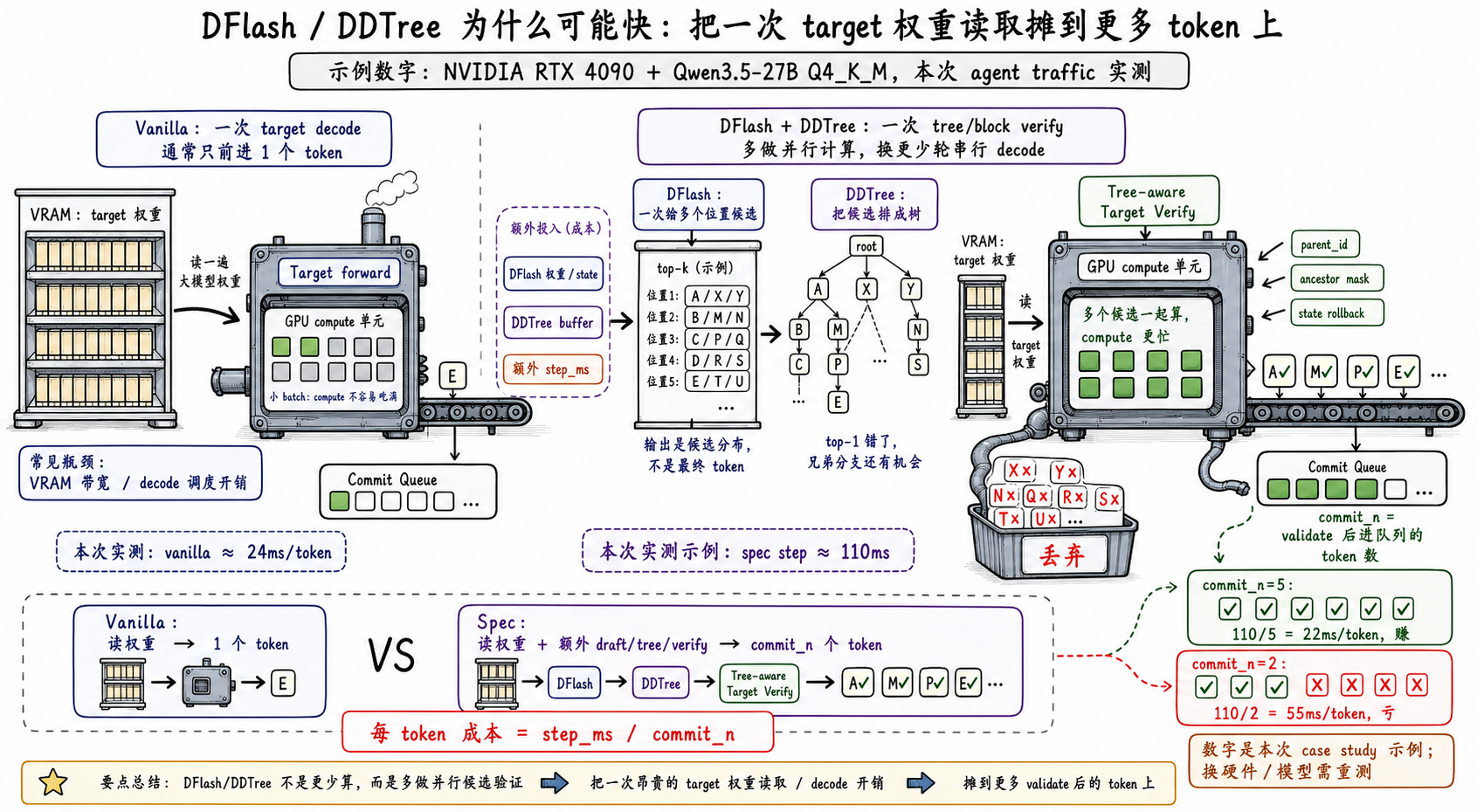
DFlash 全称是 Block Diffusion for Flash Speculative Decoding,是一个 draft 方法,通过一个额外的 draft 模型,在单次 draft forward 尽可能产出多个 token。
DDTree 全称是 Diffusion Draft Tree,是把原来的链状的数据变为基于 DFlash 给出的 top-k 分布来组织为一个树状的数据结构,让 target model 在 verify 的时候做更多可能性的验证。
DFlash + DDTree 做的是优化 proposal 和 verify 两步的吞吐量;串行太慢了,GPU 本身就是对批量计算友好的,应该尽可能改为批量处理。
换一个角度说,为了并行处理我们有额外的前置计算量,作为 trade-off,如果这些前置计算量的结果不被接受(effective acceptance length 的值不高),那么这会是负优化。
这里 DFlash 还有一个约束:DFlash 模型。目前 z-lab 官方训练 DFlash 模型的方法还没有公开,可用的 DFlash 模型目前只有 z-lab 官方提供的这些。SpecForge 提供了 DFlash 模型的训练方法,但结果和 z-lab 的结果还是有差距。
现在我能用 Local LLM + DFlash / DDTree 驱动我的 agent 了吗?
tl;dr 不能。主要的制约因素还是目前 draft model 的训练方法和训练成本还没有公开,而已经公开的(至少 Qwen3.5-27B 的这个版本)并没有为 agent 使用准备好。而除此以外,要使用 DFlash,我们还得注意计算 VRAM 的占用,draft model 也需要占用显存。RTX 3090/4090 的显存只有 24GB,这次 vLLM DFlash 路线使用的 AWQ target + BF16 draft 已经超过 24GB。最后再贴一个通过 GPT Image 2 绘制的图作为我的总结。